Relational database
A relational database provides a structured way to store data into tables consisting of rows and columns. Different tables in a relational database can be joined together using common columns from each table, forming relationships.
Analytics engineers use relational database models to process high volumes of data that, in its rawest form, is too difficult for an end user or analyst to read and comprehend. Thanks to these models, people can easily query, interpret, and derive insight out of data using the accessible SQL.
Anyone who’s ever managed or modeled data will tell you that data points are only meaningful in relation to each other. The very philosophy behind data management and data analytics has centered on forming a narrative out of seemingly disparate elements.
At the heart of this notion sits the relational database, which was first introduced by computer scientist E.F. Codd in the year 1970 — 13 years before the internet was even invented!
How relational databases work
The legwork behind relational databases lies in establishing pre-defined relationships between tables, also called “entities”. For example, in the jaffle_shop ecommerce store database where customers’ information is stored in a customers table and orders information is stored in an orders table, a relationship is defined such that each order is attributed to a customer.
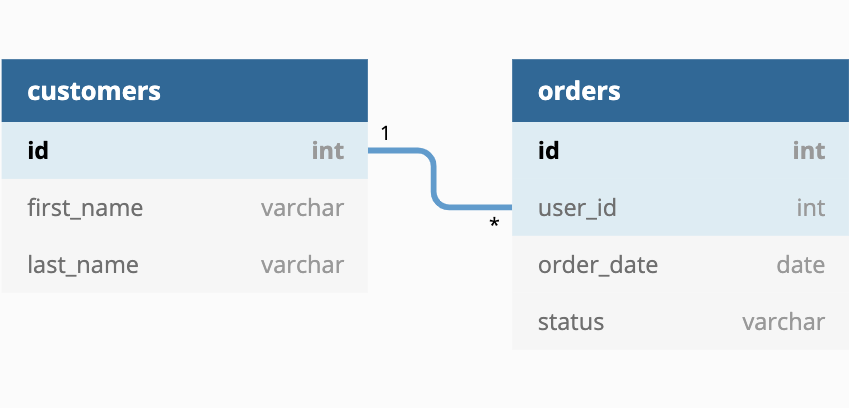
The way relationships are defined is via primary keys and foreign keys.
By definition, a primary key is a column (or combination of columns as a surrogate key) which identifies a unique record. There can be only one primary key per table, and the primary key should be unique and not null.
On the other hand, a foreign key is a column (or combination of columns) in one table that references the primary key in another table. In the above example, multiple orders can belong to one customer. Assuming that id is defined as the primary key for the customers table, user_id in the orders table would be the foreign key.
In analytics engineering, where the focus is geared towards data modeling and creating a reporting layer for a BI tool, relational databases are a great fit. Data modeling defines how the data elements are related to each other, and a well-organized database is the cornerstone of effective data querying.
Use cases for relational databases
Relational databases are best for structured data that can be organized into tables made up of rows and columns. Data teams rely on relational databases for storing transactional data, and also when data querying and data analysis is needed.
Transactional processing
As mentioned earlier, relational databases are a great fit for transaction-oriented systems such as CRM tools, e-commerce platforms, or finance software. Companies tend to use relational databases when transactional consistency is required, as they offer a near failsafe environment for data accuracy and completion. When a transaction consists of several steps, the system treats the steps as a single transaction and assures that the operation follows an ‘all-or-nothing’ scenario, ie: the steps either all survive or all fail.
Modeling data and organizing it for analysis
Relational databases support common data modeling techniques such as dimensional modeling, Data Vault, or sometimes hybrid approaches that combine different modeling techniques. Such methodologies allow teams to organize their data into useful data structures.
A data model is the overarching conceptual layer that organizes data entities and their relationships. The specific physical implementation of that data model including the definitions of data types and constraints constitutes the database schema.
Having organized data entities also helps analytics engineers and analysts build meaningful queries that derive data in a format and granularity that is otherwise not directly available in the base database.
Most analytics engineers have to deal with both relational (typically structured data) and non-relational data (typically unstructured data) coming in from multiple sources. The data is then transformed until it ultimately gets modeled into data entities using relational modeling approaches. More on non-relational databases in the following section, but in a nutshell, structured data is data that can be easily stored in a relational database system, while unstructured data is composed of formats that cannot easily (or at all) be broken down into tabular data. Common examples of unstructured data include video files, PDFs, audio files, and social media posts.
Another popular format is semi-structured data which is inherently difficult to organize into rows and columns, but contains semantic markup that makes it possible to extract the underlying information. Some examples include XML and JSON.
Relational data warehouses provide relational databases that are specifically optimized for analytical querying rather than transaction processing. Increasingly, data warehouses are providing better support for unstructured data, or data that cannot be stored in relational tables. .
Even when analytics engineers do not physically enforce relationships at the database level (many modern data warehouses allow for defining relational constraints but do not actually enforce them), they do follow a relational process. This process enables them to still organize the data into logical entities whenever possible, and in order to make sure that the data is not redundant and easily queryable.
Relational database vs. non-relational database
The main difference between a relational and non-relational database is in how they store information. Relational databases are well-suited for data that is structured and store values in tables, and non-relational databases store data in a non-tabular form called unstructured data.
As datasets are becoming dramatically more complex and less structured, the format of the ingested data can sometimes be unpredictable which makes the case for non-relational databases (also called NoSQL).
NoSQL databases are also typically better suited for granular real-time monitoring. On the other hand, relational databases make it easier to look at transformed and aggregated data, making them a more appropriate fit for reporting and analytics.
The below table summarizes the main differences between a relational and a non-relational database:
| Relational Database | Non-Relational Database | |
|---|---|---|
| Data storage | Data is stored in tables. | Data is stored in document files, graph stores, key-value stores, or wide-column stores. |
| Data format | Data is structured. | Data is mainly unstructured. |
| Usage | Mainly used for recording transactions, data modeling, and data analysis. | Mainly used to ingest large volume real-time data streams. |
| Data Integrity | The relationships and constraints defined help ensure higher data integrity. | Non-relational databases do not guarantee data integrity. |
| Scalability | Scalable at a high price tag. | Highly scalable. |
Conclusion
Relational databases store data in a systematic way, and support querying multiple tables together in order to generate business insights.
Often starting off with unorganized and chaotic data, analytics engineers leverage relational databases to bring structure and consistency to their data.
Relational databases also have a strong record of transactional consistency. While some companies are racing to embrace non-relational databases in order to handle the big volume of unstructured data, most of their workloads likely remain transactional and analytical in nature which is why relational databases are very common.